
了解如何使用 TensorFlow 将负责任的 AI 实践集成到您的 ML 工作流程中
TensorFlow 致力于通过与 ML 社区分享资源和工具的集合,帮助负责任地开发 AI 取得进展。

什么是负责任的 AI?
AI 的发展正在创造新的机会来解决具有挑战性的现实世界问题。它也引发了关于构建对每个人都有益的 AI 系统的最佳方式的新问题。

AI 的推荐最佳实践
设计 AI 系统应遵循软件开发最佳实践,同时采用以人为本的
ML 方法

公平性
随着 AI 对各行业和社会的影响越来越大,努力实现对每个人都公平且包容的系统至关重要

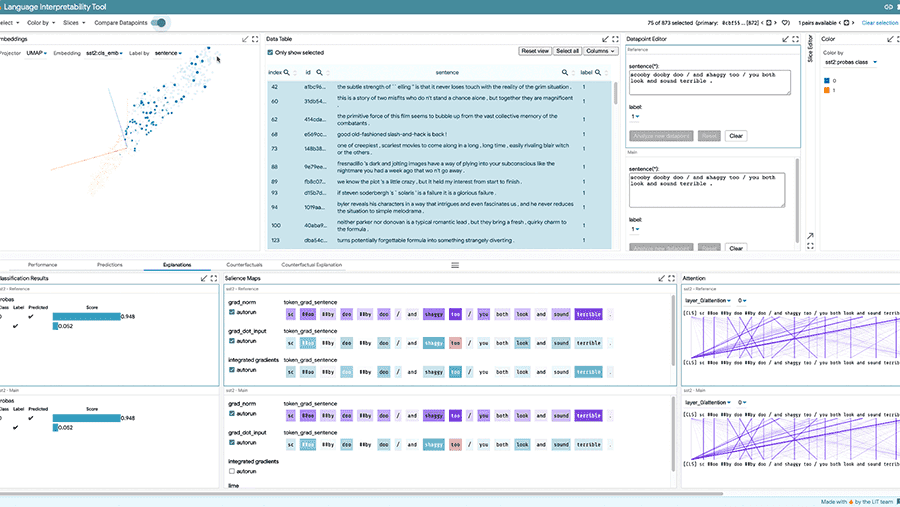
可解释性
理解和信任 AI 系统对于确保它们按预期工作至关重要

隐私
使用敏感数据训练模型需要隐私保护措施

安全性
识别潜在威胁有助于确保 AI 系统的安全
ML 工作流程中的负责任的 AI
负责任的 AI 实践可以在 ML 工作流程的每个步骤中实施。以下是一些在每个阶段需要考虑的关键问题。
我的 ML 系统适用于谁?
实际用户体验您的系统的方式对于评估其预测、推荐和决策的真实影响至关重要。确保在开发过程的早期阶段从各种用户那里获得反馈。
我是否使用了具有代表性的数据集?
您的数据是否以代表您的用户(例如,将用于所有年龄段,但您只有来自老年人的训练数据)和现实世界环境(例如,将全年使用,但您只有来自夏季的训练数据)的方式进行采样?
我的数据中是否存在现实世界/人为偏差?
数据中的潜在偏差会导致复杂的反馈循环,加剧现有的刻板印象。
我应该使用什么方法来训练我的模型?
使用训练方法将公平性、可解释性、隐私和安全性融入模型。
我的模型表现如何?
评估用户在各种用户、用例和使用环境中的现实世界场景中的体验。首先进行内部测试,然后在发布后继续进行测试。
是否存在复杂的反馈循环?
即使整个系统设计中的所有内容都经过精心设计,基于 ML 的模型在应用于真实、实时数据时也很少能达到 100% 的完美。当实时产品中出现问题时,请考虑它是否与任何现有的社会劣势相符,以及它将如何受到短期和长期解决方案的影响。
TensorFlow 的负责任的 AI 工具
TensorFlow 生态系统提供了一套工具和资源,可以帮助解决上述一些问题。
定义问题
使用以下资源设计具有负责任的 AI 的模型。

构建和准备数据
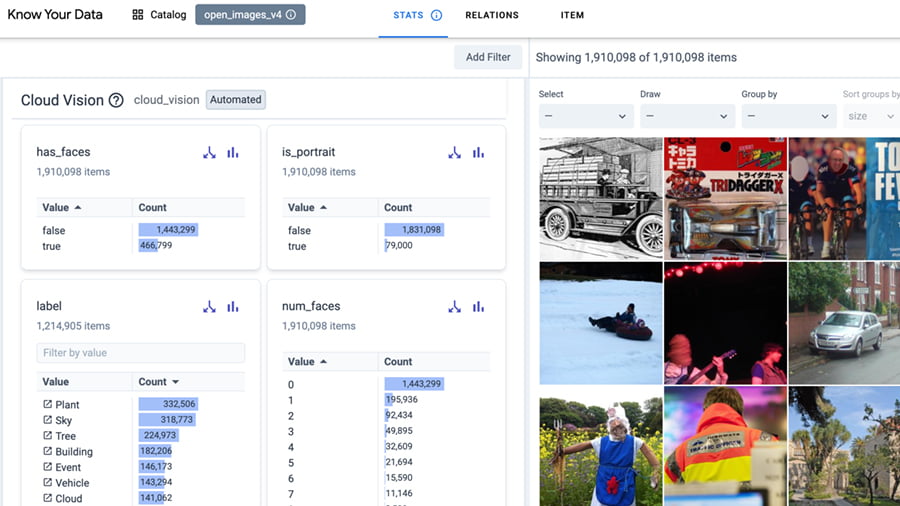
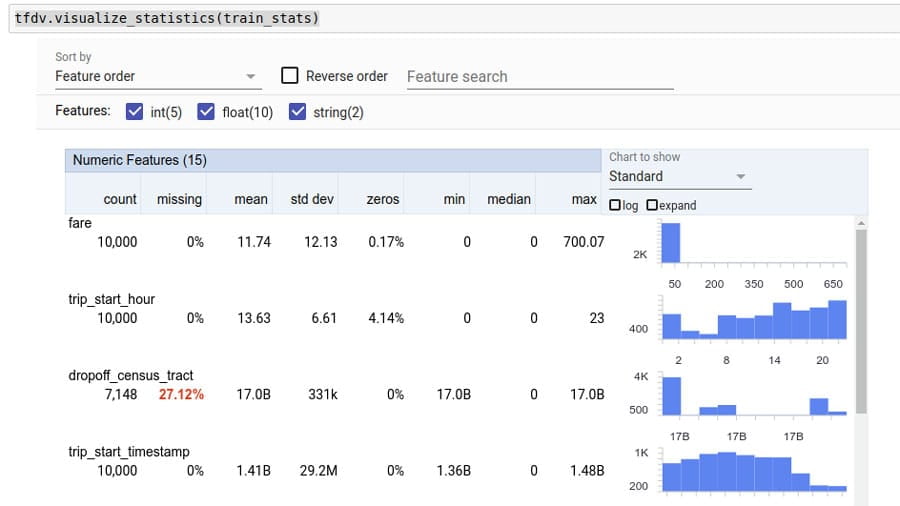
使用以下工具检查数据是否存在潜在偏差。


构建和训练模型
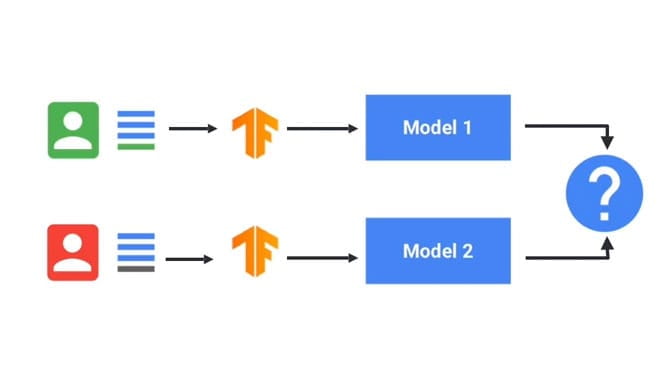
使用以下工具使用隐私保护、可解释性技术等训练模型。

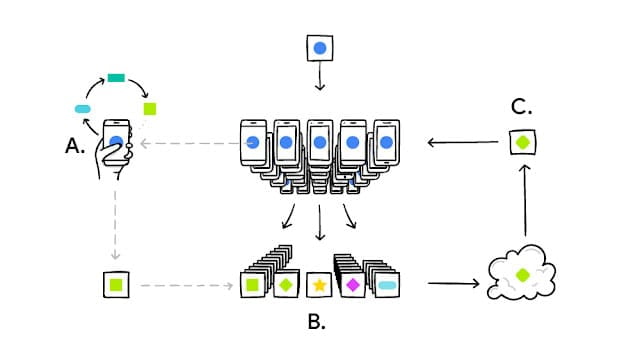
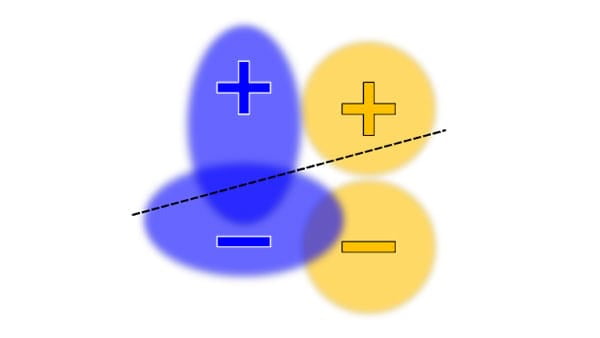
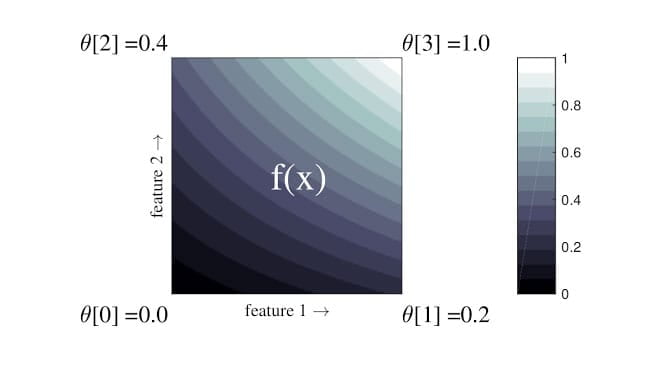
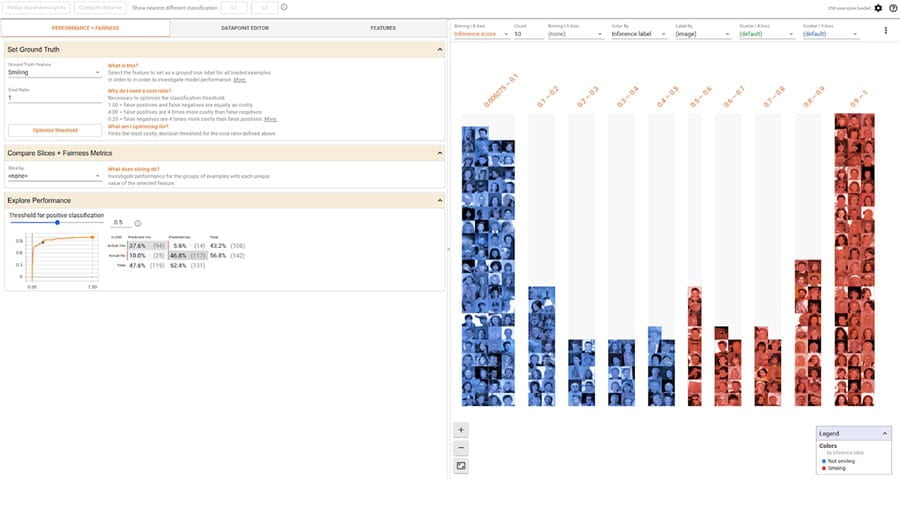
评估模型
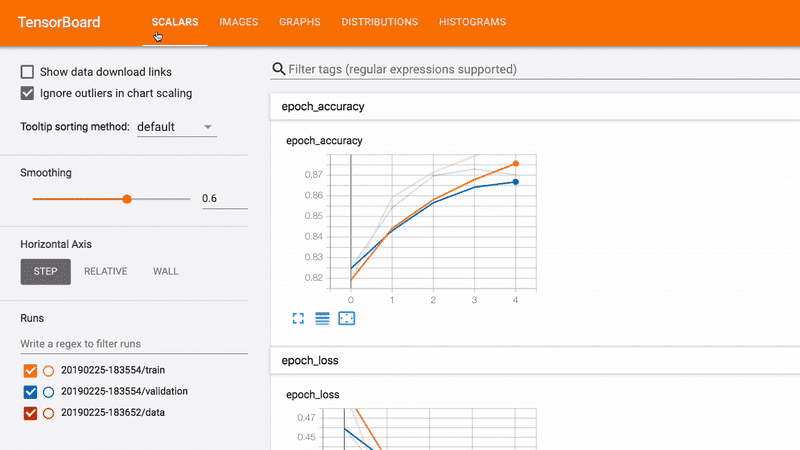
使用以下工具调试、评估和可视化模型性能。
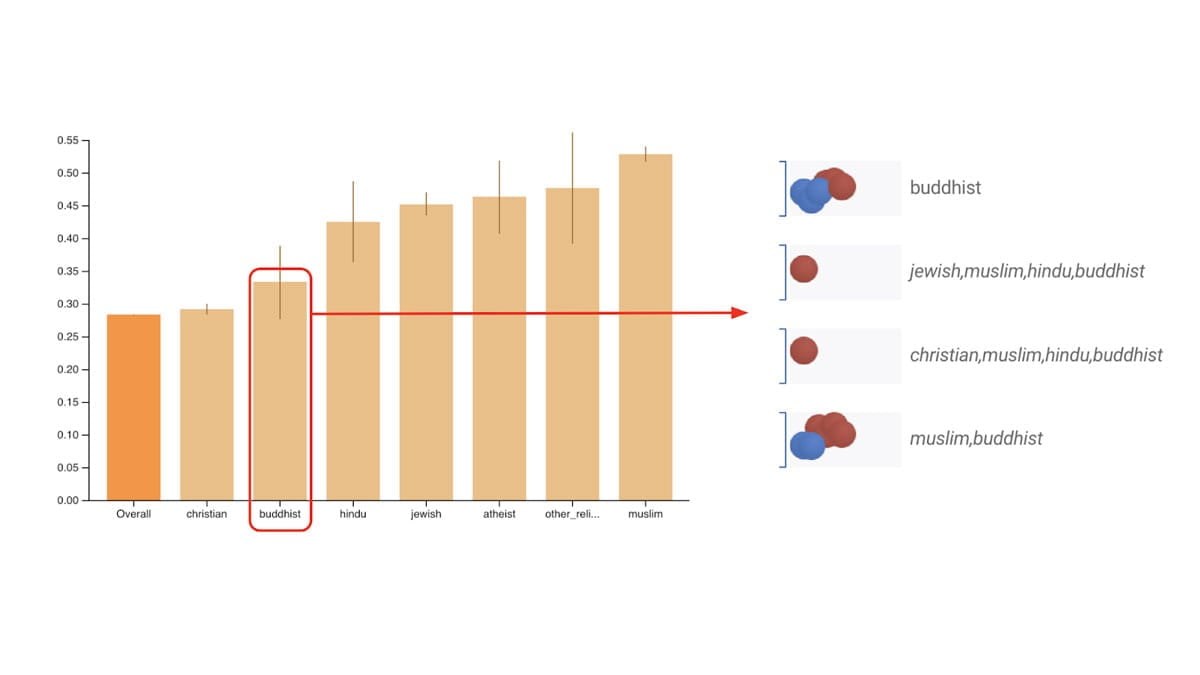
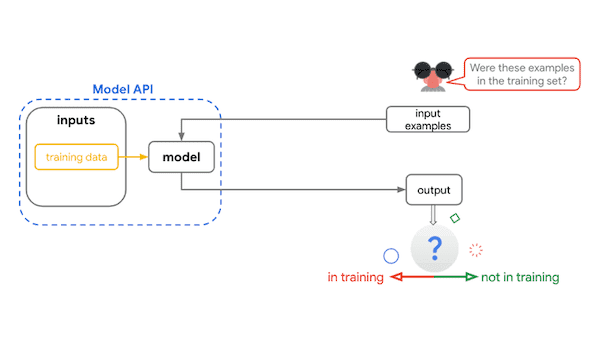
部署和监控
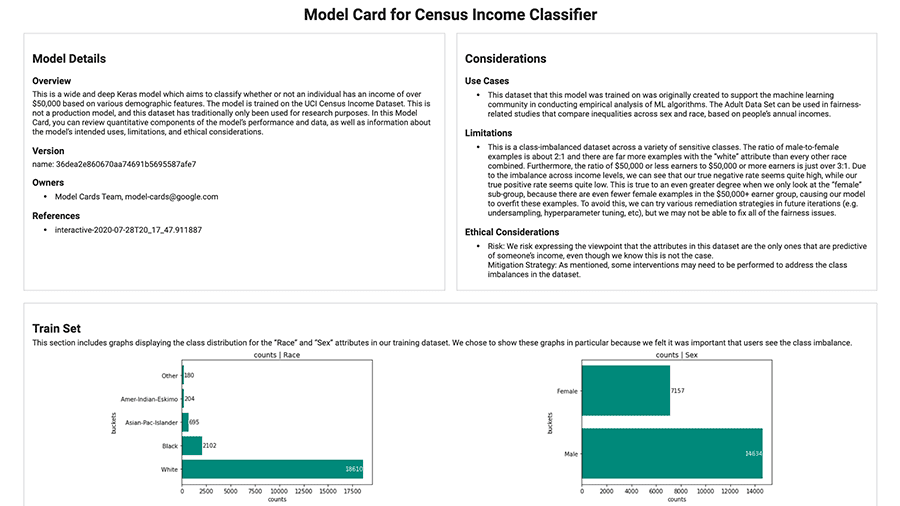
使用以下工具跟踪和交流模型上下文和详细信息。
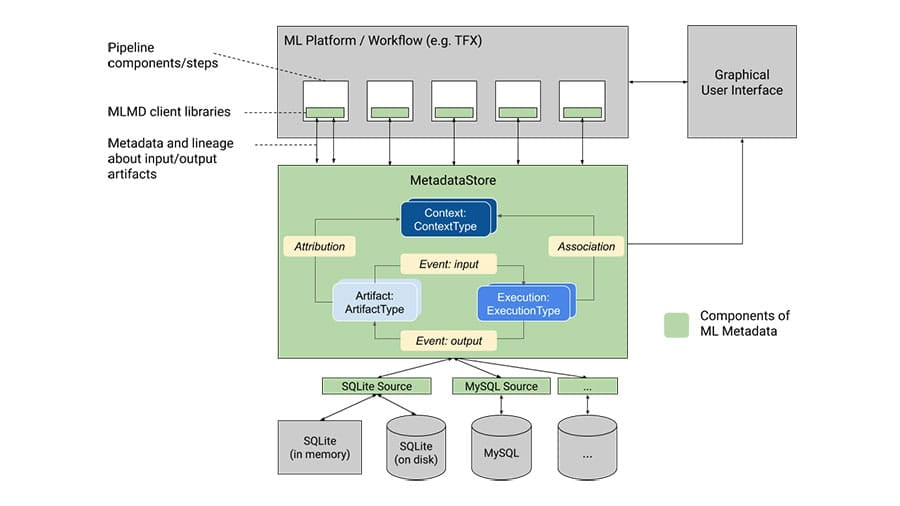
社区资源
了解社区正在做什么,并探索参与的方式。


