
|
|
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
|
概述
此笔记本使用影评文本将影评分类为正面或负面。这是一个二元分类的示例,这是一种重要且应用广泛的机器学习问题。
我们将通过从给定输入构建图来演示此笔记本中图正则化的使用。当输入不包含显式图时,使用神经结构化学习 (NSL) 框架构建图正则化模型的一般方法如下
- 为输入中的每个文本样本创建嵌入。这可以使用预训练模型完成,例如 word2vec、Swivel、BERT 等。
- 通过使用相似度度量(例如“L2”距离、“余弦”距离等)基于这些嵌入构建图。图中的节点对应于样本,图中的边对应于样本对之间的相似度。
- 从上述合成图和样本特征生成训练数据。生成的训练数据将包含邻居特征以及原始节点特征。
- 使用 Keras 顺序、函数或子类 API 创建神经网络作为基础模型。
- 使用 NSL 框架提供的 GraphRegularization 包装器类包装基础模型,以创建一个新的图 Keras 模型。此新模型将包含图正则化损失作为其训练目标中的正则化项。
- 训练和评估图 Keras 模型。
要求
- 安装神经结构化学习包。
- 安装 tensorflow-hub。
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
依赖项和导入
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
2022-12-14 12:19:13.551836: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 12:19:13.551949: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 12:19:13.551962: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly. Version: 2.11.0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-12-14 12:19:14.770677: E tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:267] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
IMDB 数据集
来自 互联网电影数据库 的 IMDB 数据集 包含 50,000 条影评的文本。这些被分成 25,000 条影评用于训练,25,000 条影评用于测试。训练集和测试集是平衡的,这意味着它们包含相同数量的正面和负面影评。
在本教程中,我们将使用 IMDB 数据集的预处理版本。
下载预处理的 IMDB 数据集
IMDB 数据集与 TensorFlow 一起打包。它已经过预处理,因此影评(单词序列)已转换为整数序列,其中每个整数代表字典中的特定单词。
以下代码下载 IMDB 数据集(如果已下载,则使用缓存副本)
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17464789/17464789 [==============================] - 0s 0us/step
参数 num_words=10000 保留训练数据中出现频率最高的 10,000 个单词。为了使词汇量的大小易于管理,罕见的单词将被丢弃。
探索数据
让我们花点时间了解数据的格式。数据集经过预处理:每个示例都是一个整数数组,代表影评的单词。每个标签都是一个整数,值为 0 或 1,其中 0 代表负面影评,1 代表正面影评。
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
影评的文本已转换为整数,其中每个整数代表字典中的特定单词。以下是第一条影评的样子
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
影评的长度可能不同。以下代码显示了第一条和第二条影评中的单词数量。由于神经网络的输入必须具有相同的长度,因此我们稍后需要解决这个问题。
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
将整数转换回单词
了解如何将整数转换回相应的文本可能很有用。在这里,我们将创建一个辅助函数来查询包含整数到字符串映射的字典对象
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1641221/1641221 [==============================] - 0s 0us/step
现在我们可以使用 decode_review 函数来显示第一条影评的文本
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
图构建
图构建涉及为文本样本创建嵌入,然后使用相似度函数来比较嵌入。
在继续之前,我们首先创建一个目录来存储本教程创建的工件。
mkdir -p /tmp/imdb
创建样本嵌入
我们将使用预训练的 Swivel 嵌入来创建 tf.train.Example 格式的嵌入,用于输入中的每个样本。我们将把生成的嵌入存储在 TFRecord 格式中,以及一个表示每个样本 ID 的附加特征。这很重要,它将使我们能够在以后将样本嵌入与图中的对应节点匹配。
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
WARNING:tensorflow:Please fix your imports. Module tensorflow.python.training.tracking.data_structures has been moved to tensorflow.python.trackable.data_structures. The old module will be deleted in version 2.11.
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
构建图
现在我们有了样本嵌入,我们将使用它们来构建一个相似性图,即图中的节点对应于样本,图中的边对应于节点对之间的相似性。
神经结构化学习提供了一个图构建库,用于根据样本嵌入构建图。它使用 余弦相似度 作为相似度度量来比较嵌入并在它们之间构建边。它还允许我们指定一个相似度阈值,该阈值可用于从最终图中丢弃不相似边。在本例中,使用 0.99 作为相似度阈值,12345 作为随机种子,我们最终得到一个具有 429,415 个双向边的图。在这里,我们使用图构建器的 局部敏感哈希 (LSH) 支持来加速图构建。有关使用图构建器 LSH 支持的详细信息,请参阅 build_graph_from_config API 文档。
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
每个双向边由输出 TSV 文件中的两个有向边表示,因此该文件包含 429,415 * 2 = 858,830 行。
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
样本特征
我们使用 tf.train.Example 格式为我们的问题创建样本特征,并将它们持久化到 TFRecord 格式中。每个样本将包含以下三个特征
- id:样本的节点 ID。
- words:包含单词 ID 的 int64 列表。
- label:一个单一的 int64,标识评论的目标类别。
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
使用图邻居增强训练数据
由于我们拥有样本特征和合成图,因此我们可以为神经结构化学习生成增强的训练数据。NSL 框架提供了一个库,用于将图和样本特征结合起来,生成用于图正则化的最终训练数据。生成的训练数据将包括原始样本特征以及它们对应邻居的特征。
在本教程中,我们考虑无向边,并使用每个样本最多 3 个邻居来使用图邻居增强训练数据。
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
基础模型
我们现在准备构建一个没有图正则化的基础模型。为了构建此模型,我们可以使用构建图时使用的嵌入,或者我们可以与分类任务一起学习新的嵌入。出于本笔记本的目的,我们将执行后者。
全局变量
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
超参数
我们将使用 HParams 的实例来包含用于训练和评估的各种超参数和常量。我们将在下面简要描述它们中的每一个
num_classes:有 2 个类别 - 正面 和 负面。
max_seq_length:这是本例中从每个电影评论中考虑的单词的最大数量。
vocab_size:这是本例中考虑的词汇量的大小。
distance_type:这是用于对样本及其邻居进行正则化的距离度量。
graph_regularization_multiplier:这控制了图正则化项在整体损失函数中的相对权重。
num_neighbors:用于图正则化的邻居数量。此值必须小于或等于在调用
nsl.tools.pack_nbrs时使用的max_nbrs参数。num_fc_units:神经网络中全连接层的单元数量。
train_epochs:训练轮数。
batch_size:用于训练和评估的批次大小。
eval_steps:在认为评估完成之前要处理的批次数量。如果设置为
None,则评估测试集中的所有实例。
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
准备数据
评论(整数数组)必须在被馈送到神经网络之前转换为张量。此转换可以通过几种方式完成
将数组转换为
0和1的向量,表示单词出现,类似于独热编码。例如,序列[3, 5]将变为一个10000维向量,除了索引3和5为 1 之外,其他所有索引都为 0。然后,将其作为网络中的第一层(一个Dense层)——它可以处理浮点向量数据。但是,这种方法需要大量的内存,需要一个num_words * num_reviews大小的矩阵。或者,我们可以填充数组,使它们都具有相同的长度,然后创建一个形状为
max_length * num_reviews的整数张量。我们可以使用能够处理此形状的嵌入层作为网络中的第一层。
在本教程中,我们将使用第二种方法。
由于电影评论必须具有相同的长度,因此我们将使用下面定义的 pad_sequence 函数来标准化长度。
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
构建模型
神经网络是通过堆叠层创建的——这需要两个主要的架构决策
- 模型中使用多少层?
- 每层使用多少隐藏单元?
在本例中,输入数据由一个单词索引数组组成。要预测的标签是 0 或 1。
在本教程中,我们将使用双向 LSTM 作为我们的基础模型。
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
这些层有效地按顺序堆叠以构建分类器
- 第一层是一个
Input层,它接受整数编码的词汇表。 - 下一层是一个
Embedding层,它接受整数编码的词汇表,并查找每个单词索引的嵌入向量。这些向量在模型训练时学习。这些向量为输出数组添加了一个维度。生成的维度为:(batch, sequence, embedding)。 - 接下来,双向 LSTM 层为每个示例返回一个固定长度的输出向量。
- 此固定长度的输出向量通过一个具有 64 个隐藏单元的全连接 (
Dense) 层。 - 最后一层与单个输出节点密集连接。使用
sigmoid激活函数,此值是一个介于 0 和 1 之间的浮点数,表示概率或置信度水平。
隐藏单元
上述模型有两个中间层或“隐藏”层,介于输入和输出之间,不包括 Embedding 层。输出(单元、节点或神经元)的数量是该层表示空间的维度。换句话说,网络在学习内部表示时允许的自由度。
如果模型具有更多隐藏单元(更高维度的表示空间)和/或更多层,那么网络可以学习更复杂的表示。但是,它会使网络的计算成本更高,并可能导致学习不必要的模式——这些模式会提高训练数据的性能,但不会提高测试数据的性能。这被称为过拟合。
损失函数和优化器
模型需要一个损失函数和一个优化器进行训练。由于这是一个二元分类问题,并且模型输出一个概率(具有 sigmoid 激活的单单元层),因此我们将使用 binary_crossentropy 损失函数。
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
创建验证集
在训练时,我们希望检查模型在以前从未见过的数据上的准确性。通过将原始训练数据的一部分分离出来,创建一个验证集。(为什么现在不使用测试集?我们的目标是仅使用训练数据来开发和调整我们的模型,然后只使用测试数据一次来评估我们的准确性)。
在本教程中,我们将大约 10% 的初始训练样本(25000 的 10%)作为训练的标记数据,其余作为验证数据。由于初始训练/测试分割是 50/50(每个 25000 个样本),因此我们现在拥有的有效训练/验证/测试分割是 5/45/50。
请注意,'train_dataset' 已经过批处理和洗牌。
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
训练模型
以小批量训练模型。在训练时,监控模型在验证集上的损失和准确性
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/keras/engine/functional.py:638: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 20s 790ms/step - loss: 0.6928 - accuracy: 0.4850 - val_loss: 0.6927 - val_accuracy: 0.5001 Epoch 2/10 21/21 [==============================] - 15s 739ms/step - loss: 0.6847 - accuracy: 0.5019 - val_loss: 0.6387 - val_accuracy: 0.5028 Epoch 3/10 21/21 [==============================] - 15s 741ms/step - loss: 0.6641 - accuracy: 0.5350 - val_loss: 0.6572 - val_accuracy: 0.5002 Epoch 4/10 21/21 [==============================] - 15s 740ms/step - loss: 0.6083 - accuracy: 0.5504 - val_loss: 0.5291 - val_accuracy: 0.7685 Epoch 5/10 21/21 [==============================] - 15s 742ms/step - loss: 0.4911 - accuracy: 0.7635 - val_loss: 0.4327 - val_accuracy: 0.8143 Epoch 6/10 21/21 [==============================] - 15s 741ms/step - loss: 0.3924 - accuracy: 0.8304 - val_loss: 0.3821 - val_accuracy: 0.8529 Epoch 7/10 21/21 [==============================] - 15s 746ms/step - loss: 0.3449 - accuracy: 0.8612 - val_loss: 0.3550 - val_accuracy: 0.8145 Epoch 8/10 21/21 [==============================] - 16s 753ms/step - loss: 0.2954 - accuracy: 0.8796 - val_loss: 0.3103 - val_accuracy: 0.8671 Epoch 9/10 21/21 [==============================] - 16s 767ms/step - loss: 0.3243 - accuracy: 0.8719 - val_loss: 0.3371 - val_accuracy: 0.8733 Epoch 10/10 21/21 [==============================] - 16s 768ms/step - loss: 0.2918 - accuracy: 0.8765 - val_loss: 0.2845 - val_accuracy: 0.8944
评估模型
现在,让我们看看模型的表现。将返回两个值。损失(表示我们错误的数字,越低越好)和准确性。
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 14s 69ms/step - loss: 0.3740 - accuracy: 0.8502 [0.37399888038635254, 0.8502399921417236]
创建随时间变化的准确性/损失图
model.fit() 返回一个 History 对象,其中包含一个字典,其中包含训练期间发生的所有事件
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
总共有四个条目:一个用于训练和验证期间监控的每个指标。我们可以使用它们来绘制训练和验证损失以进行比较,以及训练和验证准确性
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
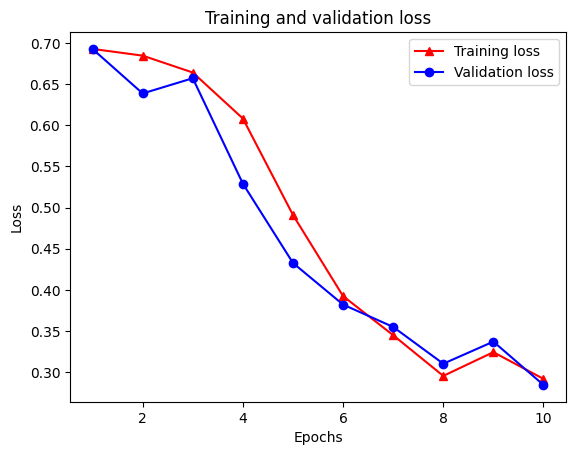
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
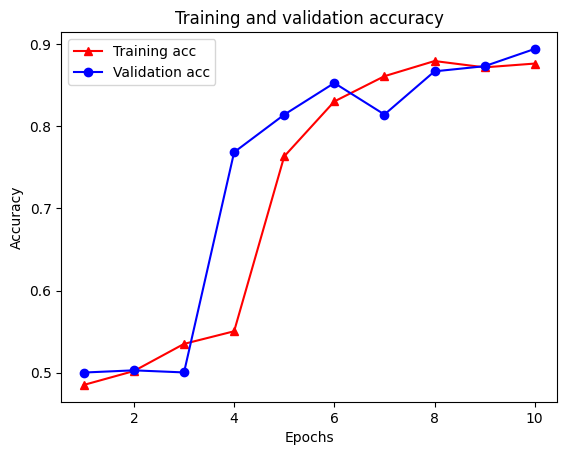
请注意,训练损失在每个时期减少,训练准确性在每个时期增加。这在使用梯度下降优化时是预期的——它应该在每次迭代中最小化所需的数量。
图正则化
我们现在准备尝试使用上面构建的基础模型进行图正则化。我们将使用神经结构化学习框架提供的 GraphRegularization 包装类来包装基础(双向 LSTM)模型,以包含图正则化。训练和评估图正则化模型的其余步骤与基础模型类似。
创建图正则化模型
为了评估图正则化的增量益处,我们将创建一个新的基础模型实例。这是因为 model 已经训练了几次迭代,并且重新使用此训练过的模型来创建图正则化模型对于 model 来说将不是一个公平的比较。
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
训练模型
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10 WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089 WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089 21/21 [==============================] - 27s 920ms/step - loss: 0.6938 - accuracy: 0.4858 - scaled_graph_loss: 3.3994e-05 - val_loss: 0.6928 - val_accuracy: 0.5024 Epoch 2/10 21/21 [==============================] - 17s 836ms/step - loss: 0.6921 - accuracy: 0.5085 - scaled_graph_loss: 2.2528e-05 - val_loss: 0.6916 - val_accuracy: 0.4987 Epoch 3/10 21/21 [==============================] - 18s 844ms/step - loss: 0.6806 - accuracy: 0.5088 - scaled_graph_loss: 0.0018 - val_loss: 0.6383 - val_accuracy: 0.6404 Epoch 4/10 21/21 [==============================] - 17s 837ms/step - loss: 0.6143 - accuracy: 0.6588 - scaled_graph_loss: 0.0292 - val_loss: 0.5993 - val_accuracy: 0.5436 Epoch 5/10 21/21 [==============================] - 17s 841ms/step - loss: 0.5748 - accuracy: 0.7015 - scaled_graph_loss: 0.0563 - val_loss: 0.4726 - val_accuracy: 0.8239 Epoch 6/10 21/21 [==============================] - 18s 847ms/step - loss: 0.5366 - accuracy: 0.8019 - scaled_graph_loss: 0.0681 - val_loss: 0.4708 - val_accuracy: 0.7508 Epoch 7/10 21/21 [==============================] - 18s 847ms/step - loss: 0.5330 - accuracy: 0.7992 - scaled_graph_loss: 0.0722 - val_loss: 0.4462 - val_accuracy: 0.8373 Epoch 8/10 21/21 [==============================] - 18s 848ms/step - loss: 0.5207 - accuracy: 0.8096 - scaled_graph_loss: 0.0755 - val_loss: 0.4772 - val_accuracy: 0.7738 Epoch 9/10 21/21 [==============================] - 18s 851ms/step - loss: 0.5139 - accuracy: 0.8319 - scaled_graph_loss: 0.0831 - val_loss: 0.4223 - val_accuracy: 0.8412 Epoch 10/10 21/21 [==============================] - 18s 851ms/step - loss: 0.4959 - accuracy: 0.8377 - scaled_graph_loss: 0.0813 - val_loss: 0.4332 - val_accuracy: 0.8199
评估模型
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 15s 70ms/step - loss: 0.4728 - accuracy: 0.7732 [0.4728052020072937, 0.7731599807739258]
创建随时间变化的准确性/损失图
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
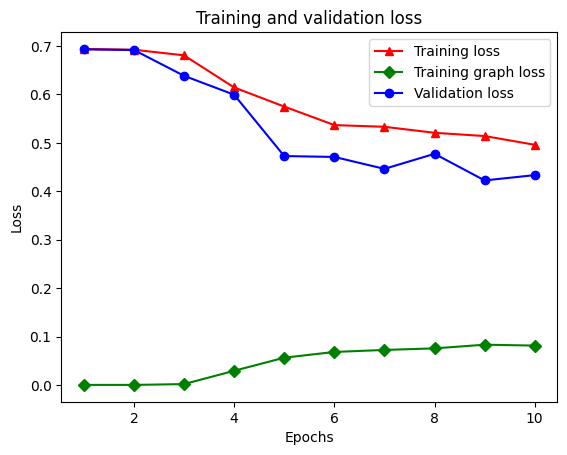
字典中总共有五个条目:训练损失、训练准确性、训练图损失、验证损失和验证准确性。我们可以将它们全部绘制在一起以进行比较。请注意,图损失仅在训练期间计算。
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
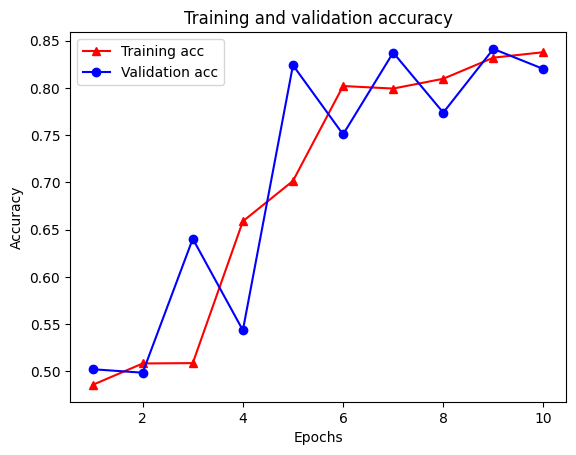
半监督学习的力量
半监督学习,更具体地说,在本教程中提到的图正则化,在训练数据量较少的情况下非常有效。通过利用训练样本之间的相似性,可以弥补训练数据不足的问题,而传统的有监督学习无法做到这一点。
我们将**监督率**定义为训练样本数量与总样本数量(包括训练、验证和测试样本)的比率。在本笔记本中,我们使用 0.05 的监督率(即标记数据的 5%)来训练基础模型和图正则化模型。我们在下面的单元格中说明了监督率对模型精度的影响。
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 640x480 with 0 Axes>
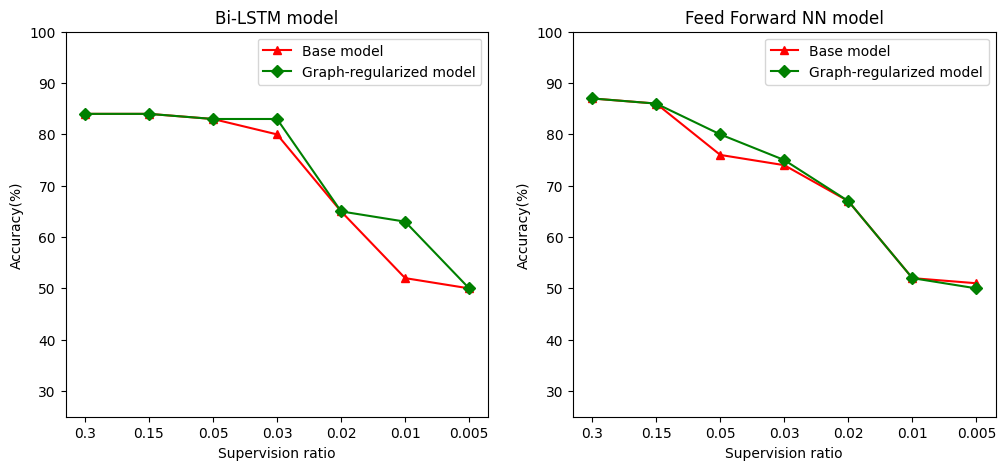
可以观察到,随着监督率的降低,模型精度也会降低。这对于基础模型和图正则化模型都是成立的,无论使用哪种模型架构。但是,请注意,图正则化模型在两种架构中都比基础模型表现更好。特别是对于 Bi-LSTM 模型,当监督率为 0.01 时,图正则化模型的精度比基础模型高**约 20%**。这主要是因为图正则化模型使用了半监督学习,除了训练样本本身之外,还利用了训练样本之间的结构相似性。
结论
我们演示了使用神经结构化学习 (NSL) 框架进行图正则化,即使输入不包含显式图。我们考虑了 IMDB 电影评论的情感分类任务,为此我们根据评论嵌入合成了一个相似性图。我们鼓励用户通过改变超参数、监督量和使用不同的模型架构来进一步实验。